
The goal of this paper is to introduce the Deep Recursive Residual Network (DRRN), a type of CNN with the goal of providing a deep and effective model that uses many fewer parameters and has a higher performance than competing single image super-resolution (SISR) models.
The authors are motivated by recent models that achieve improved performance in super resolution reconstruction by adding many more layers (as many as 30) than previous designs (usually no more than 5). A pitfall of these deep models are their very large parameters. The described DRRN has significantly fewer parameters (2-14x less) while maintaining depth, with most DRRN models having as many as 52 layers.
Residual networks use an identity branch to retain the input to a residual block. Then, the block only optimizes the residual mapping between the input and output instead of optimizing the mapping from input to output directly.
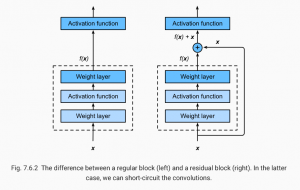 In the picture above (from the open source textbook ‘Dive into Deep Learning’), the difference between a regular (on the left) and residual block (right) is shown. The mapping output generated by the regular block, f(x), contains x more information than the residual block, and thus requires more computations. Residual blocks simplify the amount of input required and thus reduce computations.
In the picture above (from the open source textbook ‘Dive into Deep Learning’), the difference between a regular (on the left) and residual block (right) is shown. The mapping output generated by the regular block, f(x), contains x more information than the residual block, and thus requires more computations. Residual blocks simplify the amount of input required and thus reduce computations.
The output of a SR model is anticipated to be highly similar to the input, so DRRN uses both residual learning. It employs both global residual learning, which connects the input and output images, and local residual learning, which ties the input and output of every few layers.
DRRN uses a recursive block of residual units that share weights to keep the model size small even though it is deep. Adding more depth (and consequently improving accuracy) can be done without adding more weight parameters. It uses a multi-path structure in the recursive block to avoid the vanishing/exploding gradients problem that appears in very deep models.
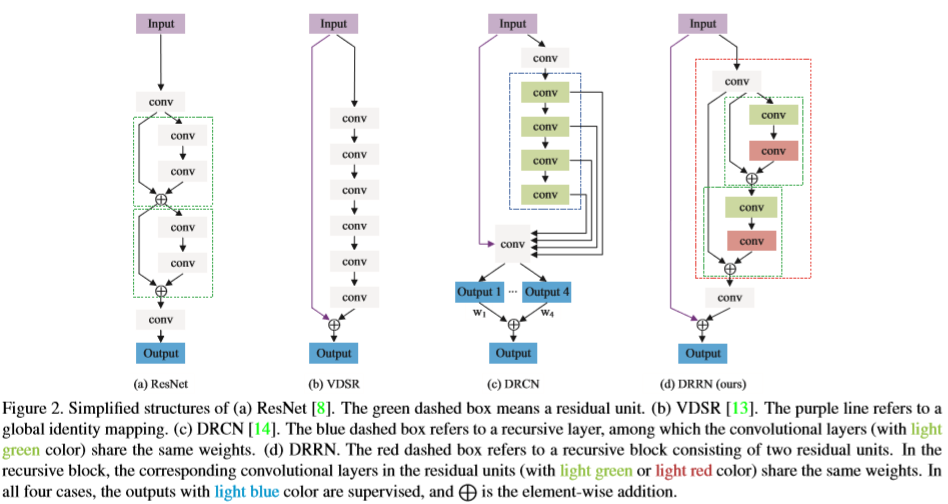
The figure above, taken from the paper by Tai et al., compares the basic structure of DRRN with other popular deep SR frameworks.
By combining global and local residual learning, the authors achieve visibly finer resolution than competing networks. Weight sharing in the recursive model allows them to deepen their network without requiring many parameters. Implementations of DRRN are available in tensorflow and pytorch in addition to the original caffe implementation (X).
The DRRN architecture may be very useful for our lab. Accurately and efficiently mapping low resolution images to corresponding high resolution images is a priority of our microscopy research. When comparing to a previous post describing the UNet, a different type of CNN, we found that while both are fast, highly effective networks, their purposes diverge. As stated earlier, DRRN models are designed for effective single-shot super-resolution, a central focus of our research, while Unet models are designed for image segmentation and multi-categorization. While this is a potential extension of our research, it appears that the DRRN model better fits the needs of our current research.
References
Y. Tai, J. Yang and X. Liu, “Image Super-Resolution via Deep Recursive Residual Network,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, 2017, pp. 2790-2798.
doi: 10.1109/CVPR.2017.298
A. Zhang, Z.C. Lipton, M. Li and A.J. Smola, Dive into Deep Learning (X)