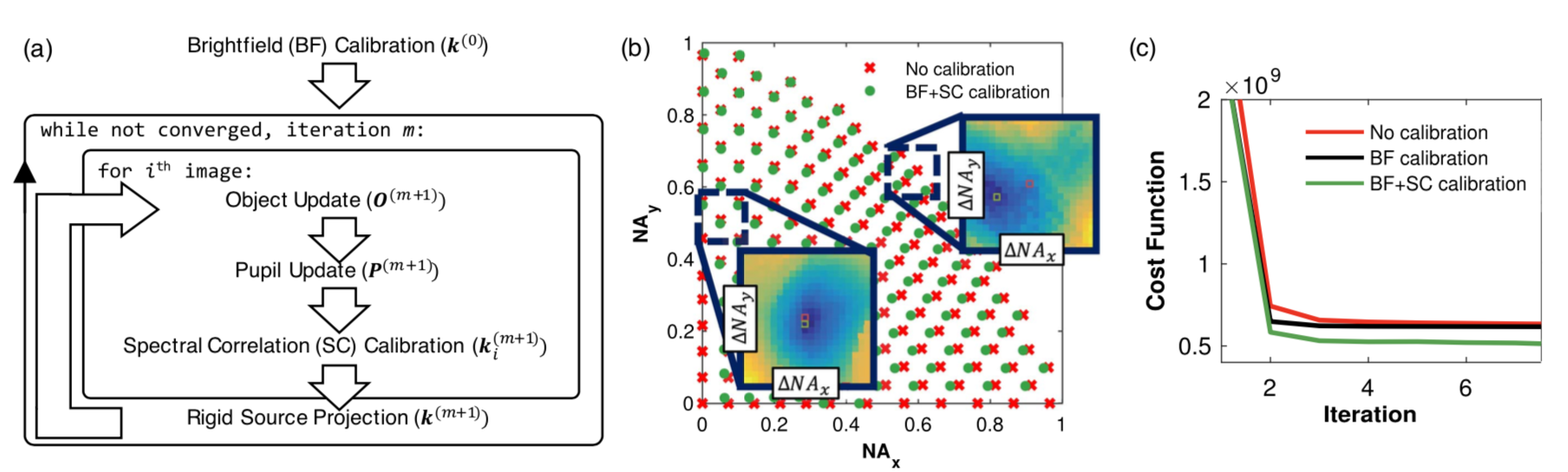
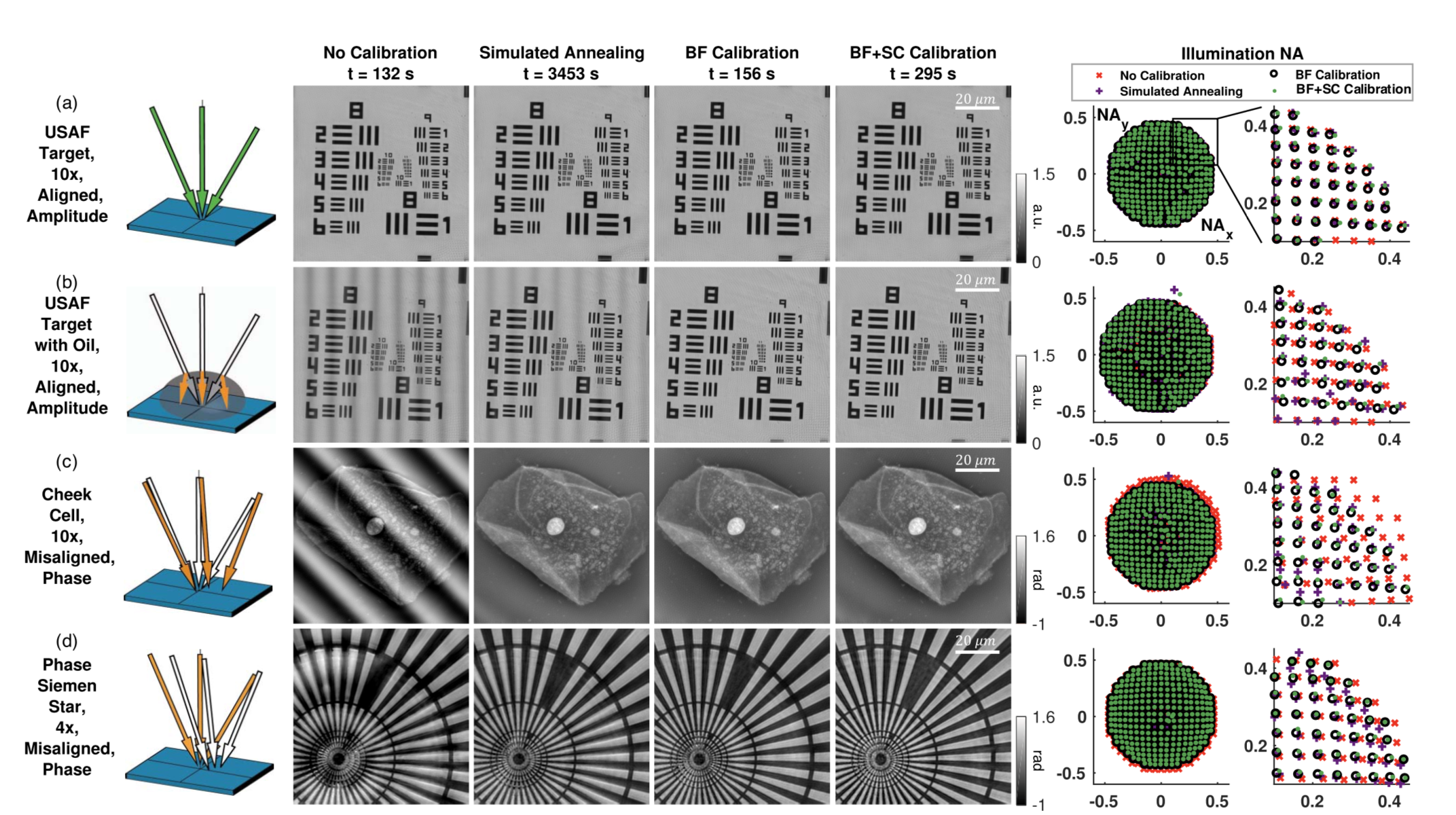
Convolutional neural networks excel at visualization tasks, and are popular for tasks like single image super resolution (SR), where a high-resolution image is generated from a single low resolution input. SR is an ill-posed problem because for any one low resolution image, many high resolution interpretations are possible.
CNNs can learn the relationship between low-resolution images and their high-resolution counterparts. Generally, deeper neural networks are better able to generate these mappings. However, it is important that deep neural networks handle input data efficiently. Otherwise, they waste computational resources on information that will not cause the high-resolution output image to be more detailed or accurate.
Many CNNs developed for SR treat low and high frequency information from input images as equally necessary to computation. Low frequency information, which expresses gradual change in pixel intensity across the image, is easily extracted from low-resolution images. It can be forwarded more or less directly to the high-resolution output. High frequency information is an abrupt change in pixel intensity. It occurs in places of sharp intensity change, like edges. This is the detail that SR attempts to recover in order to generate a high-resolution output.
The network described in this paper, called RCAN (residual channel attention network), adaptively learns the most useful features of input images. It uses a residual in residual structure to make the extremely deep network easier to train. Long and short skip connections allow the network to forward low frequency information directly toward the end of the architecture. The main portion of the network can therefore be dedicated to learning more useful high frequency information.
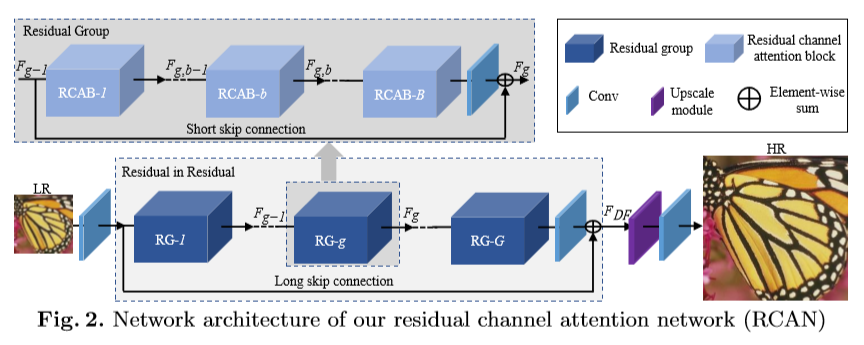
Above, a graphic from Zhang et al.’s paper illustrates the architecture of their network.
The RCAN network uses a post-upscaling strategy. Unlike other techniques, RCAN does not interpolate the low resolution input to the size of the output image before feeding it into the neural network. Preemptively enlarging the image increases the computational work that must be done and loses detail. Upscaling as a near-final step increases the efficiency of the network and preserves detail, resulting in more accurate outputs.
The residual in residual (RIR) structure used by RCAN pairs stacked residual blocks with a long skip connection. This allows the authors to have a very deep network (1,000+ layers) without making it impossible to train. They use a channel attention mechanism to emphasize network attention to the most useful information contained within the low resolution input. This most useful information is high frequency detail information, and is isolated by exploiting interdependencies between the network’s feature channels.
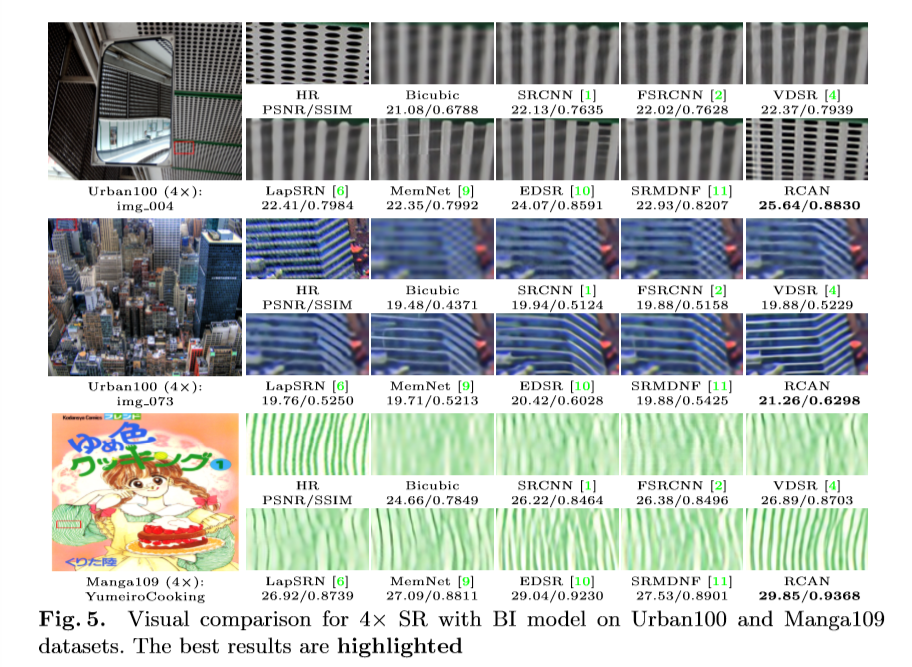
RCAN is shown by the authors to outperform other SR techniques, as shown below.